import requests, zipfile, io
import tempfile as tf
import pandas as pd
import seaborn as sb
import matplotlib.pyplot as pltProduction and Sale of Greenhouse Flowers and Plants - Open Canada
Pairs Plot
Open Canada
Software:Python
Software:R
zipfiles
csv files
Data Provider
Statistics Canada’s Open Government is a free and open-access platform containing over 80,000 datasets across diverse subjects. The purpose of sharing all data documents with the public is to remain transparent and accessible.
Dataset can be discovered by multiple searching methods here, such as Browse by subject, Open Government Portal for direct keywords search, Open Maps which contains geospatial information data, Open Data Inventory from the government of Canada organization, Apps Gallery for representing those mobile and web-based application data, Open Data 101 for letting people know how to use dataset and so on.
Production and Sales of Greenhouse flowers and plants
The annual production and sales of different types of flowers and plants from 2007 to 2019 in Canada is compiled with its metadata file here. The metadata contains detailed variable descriptions. The dataset and supporting documentation can are available from Statistics Canada.
Variables include years from 2007 to 2019, province of production, flower and plant types, and production count and sales.
Libraries
library(tidyverse)
library(GGally)Organizing Dataset
The following code is used to obtain and organize the dataset and separate it into two by output type (sales and production).
# Download the zip file of plant sales and production
temp = tf.TemporaryFile()
url = "https://www150.statcan.gc.ca/n1/tbl/csv/32100246-eng.zip"
r = requests.get(url)
temp = zipfile.ZipFile(io.BytesIO(r.content))
file_list = temp.namelist()
print(file_list)['32100246.csv', '32100246_MetaData.csv']
plants = pd.read_csv(temp.open(file_list[0]))
# Rename a couple of columns
plants = plants.rename(columns = {"GEO" : "location", "REF_DATE" : "year"})# Download the zip file of plant sales and production
temp <- tempfile()
download.file("https://www150.statcan.gc.ca/n1/tbl/csv/32100246-eng.zip",temp)
(file_list <- as.character(unzip(temp, list = TRUE)$Name))[1] "32100246.csv" "32100246_MetaData.csv"plants <- read_csv(unz(temp, file_list[1]))
unlink(temp) # Delete temp file
# Rename a couple of columns
plants <- plants |>
rename(year = REF_DATE, location = GEO) |> # personal preference for these names
rename_all(make.names)# R friendly naming that replaces spaces with '.'Greenhouse plants production and sales in Canada
The following code is used to plot greenhouse plant production and sales in Canada
# Subset a dataset of plants production in Canada
sb.set_style("darkgrid")
sb.lineplot(data = plants[(plants["location"] == "Canada") &
(plants["Output"] == "Production (number)")],
x = "year",
y = "VALUE",
hue = "Flowers and plants")
plt.ylabel("Production (number)")
plt.title("Greenhouse plants production in Canada")
plt.legend(title = "Flowers and Plants",
bbox_to_anchor=(1.05, 1),
loc='upper left',
borderaxespad=0)
plt.show();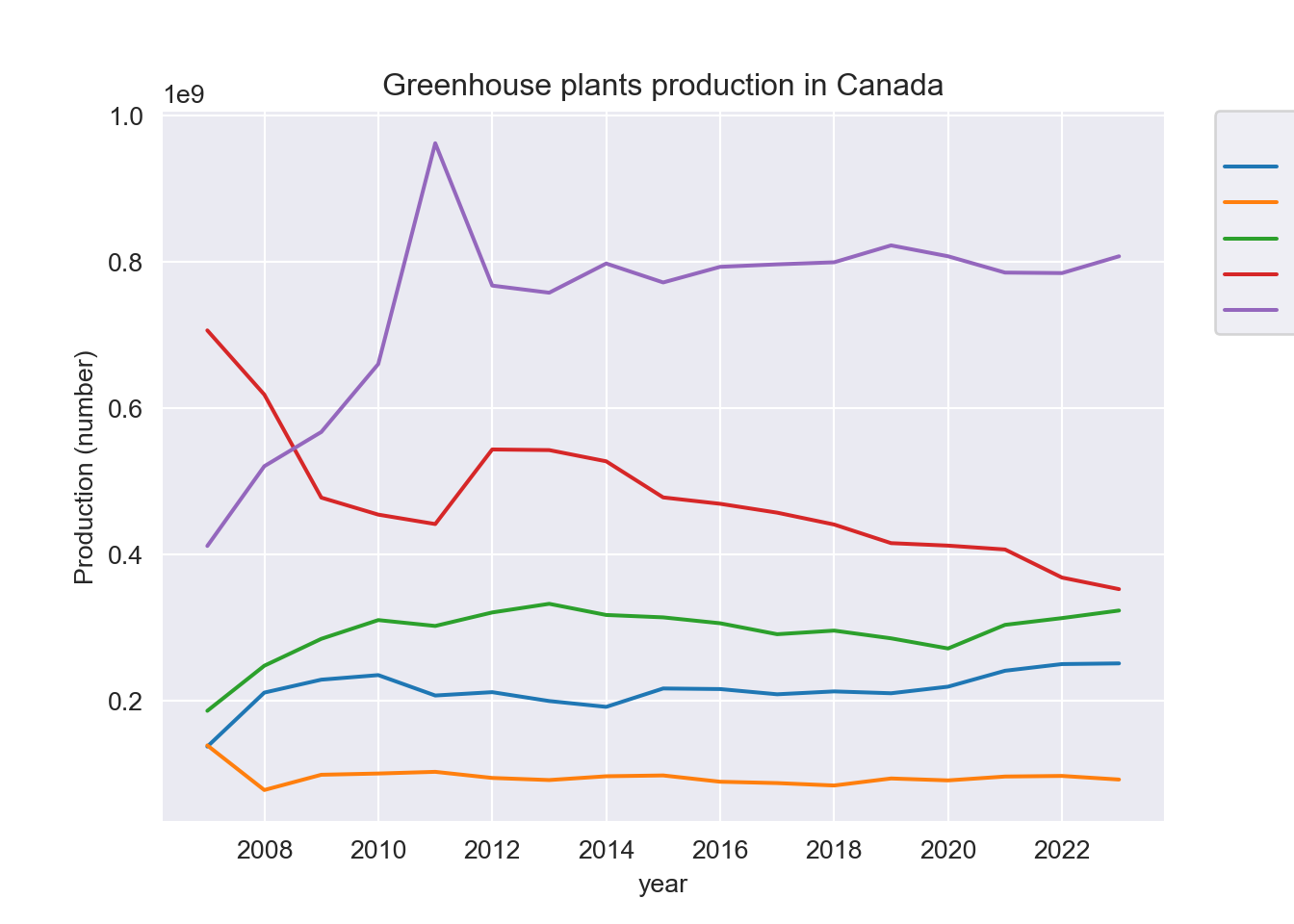
fig, ax = plt.subplots(figsize=(8, 5), constrained_layout=True)
sb.lineplot(data = plants[(plants["location"] == "Canada") &
(plants["Output"] == "Sales")],
x = "year",
y = "VALUE",
hue = "Flowers and plants",
ax = ax)
ax.set_ylabel("Production (number)")
ax.set_title("Greenhouse plants sales in Canada")
ax.legend(title = "Flowers and Plants",
bbox_to_anchor=(1.05, 1),
loc='upper left',
borderaxespad=0)
plt.show();
# Subset a dataset of plants production in Canada
plants |> subset(location == "Canada" & Output =="Production (number)") |>
ggplot( aes(x = year, y = VALUE, group = Flowers.and.plants)) +
labs(y = "Production (number)", title = "Greenhouse plants production in Canada") +
geom_line(aes(color = Flowers.and.plants))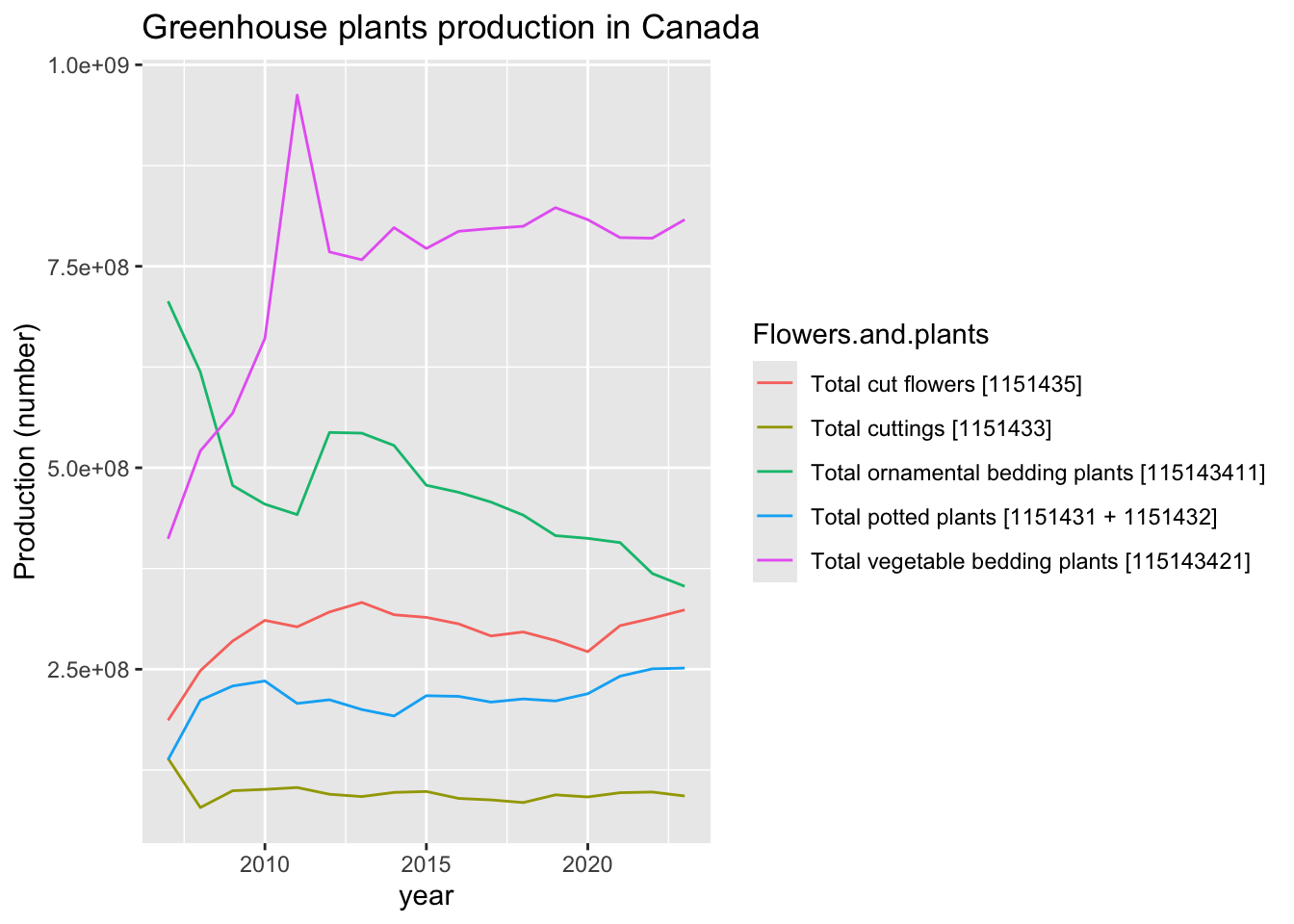
plants |> subset(location == "Canada" & Output =="Sales") |>
ggplot( aes(x = year, y = VALUE, group = Flowers.and.plants)) +
labs(y = "Sales ($ dollars)", title = "Greenhouse plants sales in Canada") +
geom_line(aes(color = Flowers.and.plants))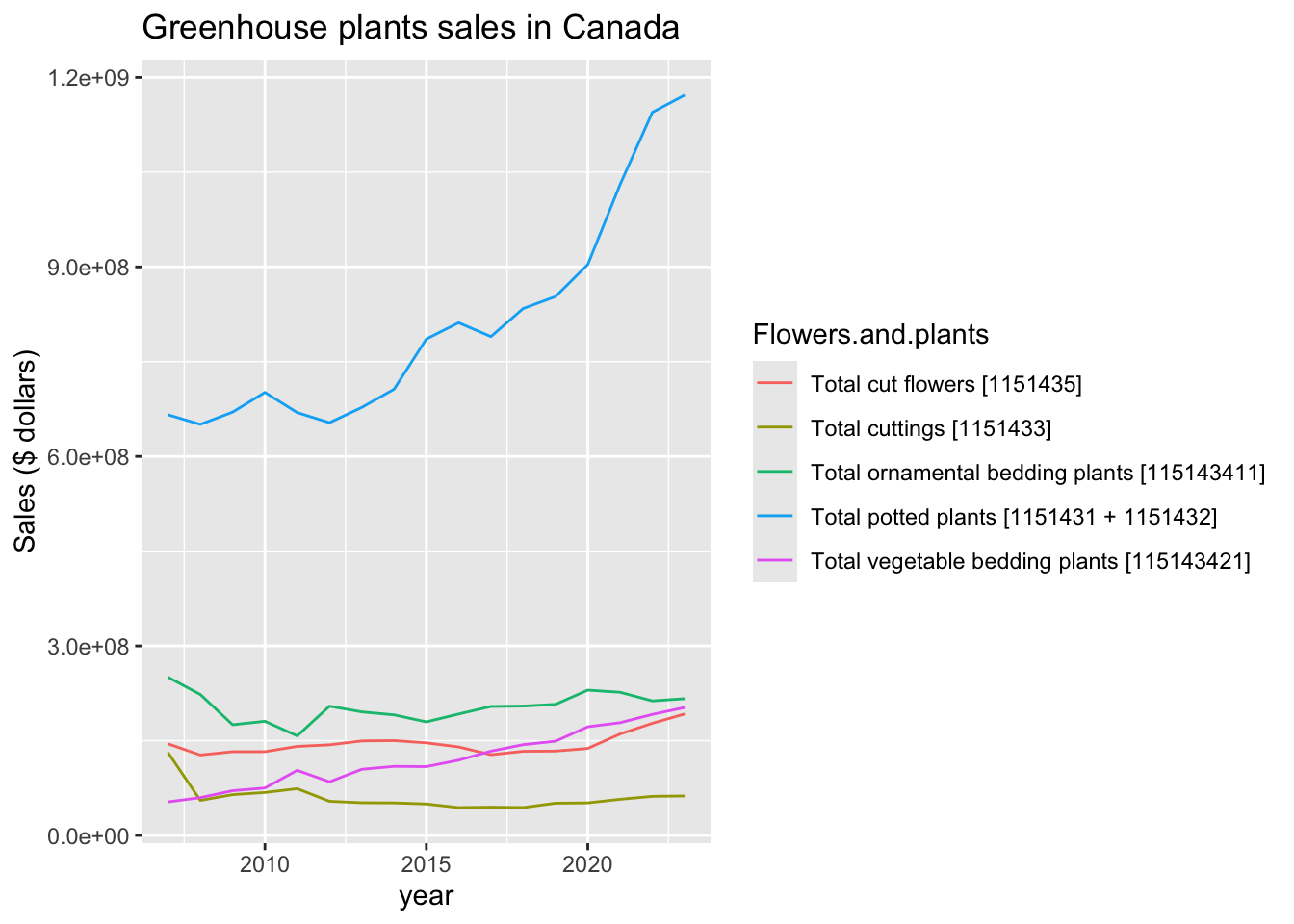
- So, the following code is used to discover the plant production in different provinces.
Bedding plants (vegetables & ornamental) production
# Select the datasets of two different bedding plants (vegetable & ornamental) in 10 different provinces
fig, ax = plt.subplots(figsize=(8, 5), constrained_layout=True)
sb.lineplot(data = plants[(plants["location"] != "Canada") &
(plants["Output"] == "Production (number)") &
(plants["Flowers and plants"] ==
"Total vegetable bedding plants [115143421]")],
x = "year",
y = "VALUE",
hue = "location",
ax = ax)
ax.set_ylabel("Number Produced")
ax.set_title("Total vegetable bedding plants production")
ax.legend(title = "Province",
bbox_to_anchor=(1.05, 1),
loc='upper left',
borderaxespad=0)
plt.show();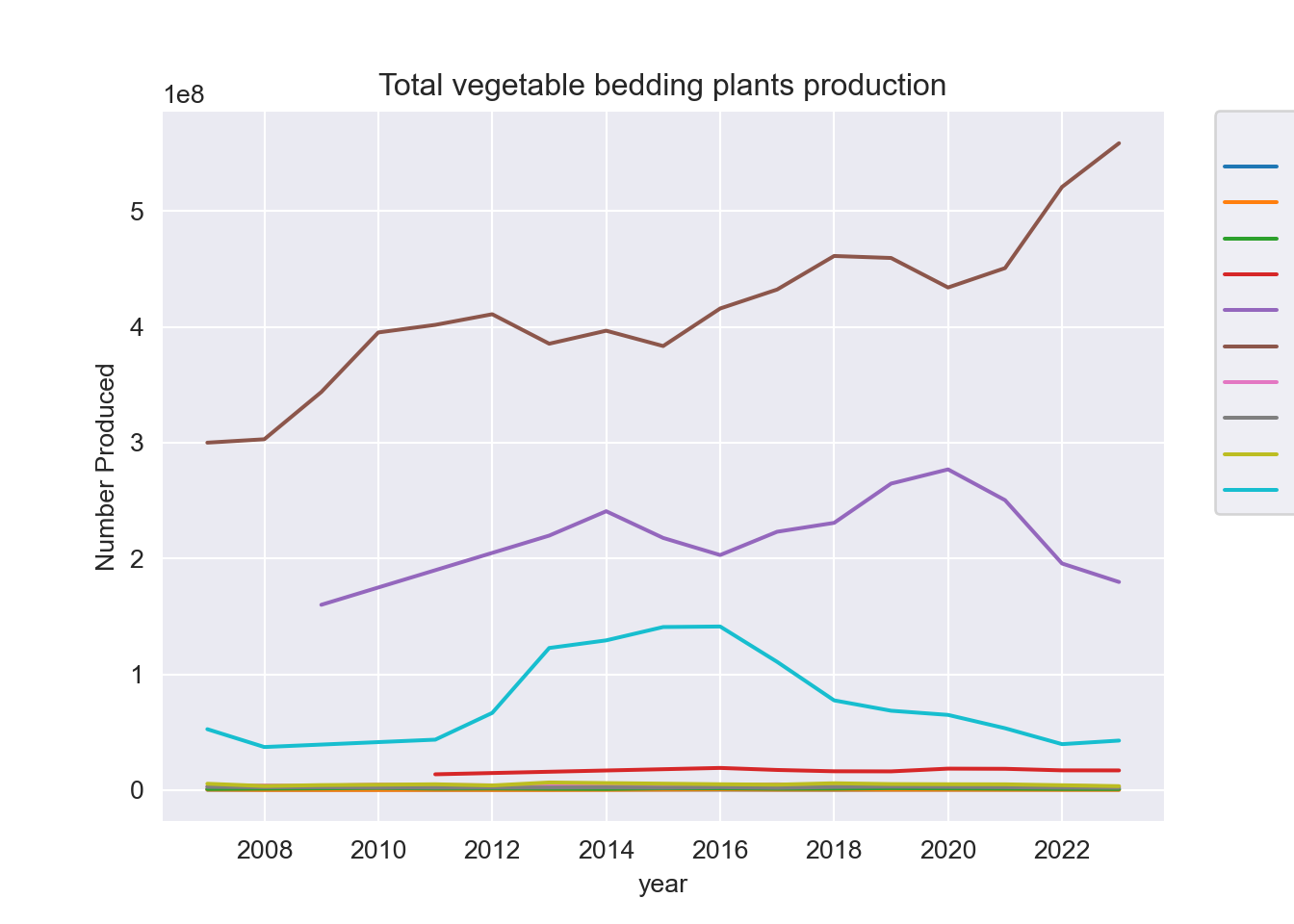
fig, ax = plt.subplots(figsize=(8, 5), constrained_layout=True )
sb.lineplot(data = plants[(plants["location"] != "Canada") &
(plants["Output"] == "Production (number)") &
(plants["Flowers and plants"] == "Total ornamental bedding plants [115143411]")],
x = "year",
y = "VALUE",
hue = "location",
ax = ax)
ax.set_ylabel("Number Produced")
ax.set_title("Total ornamental bedding plants production")
ax.legend(title = "Province",
bbox_to_anchor=(1.05, 1),
loc='upper left',
borderaxespad=0)
plt.show();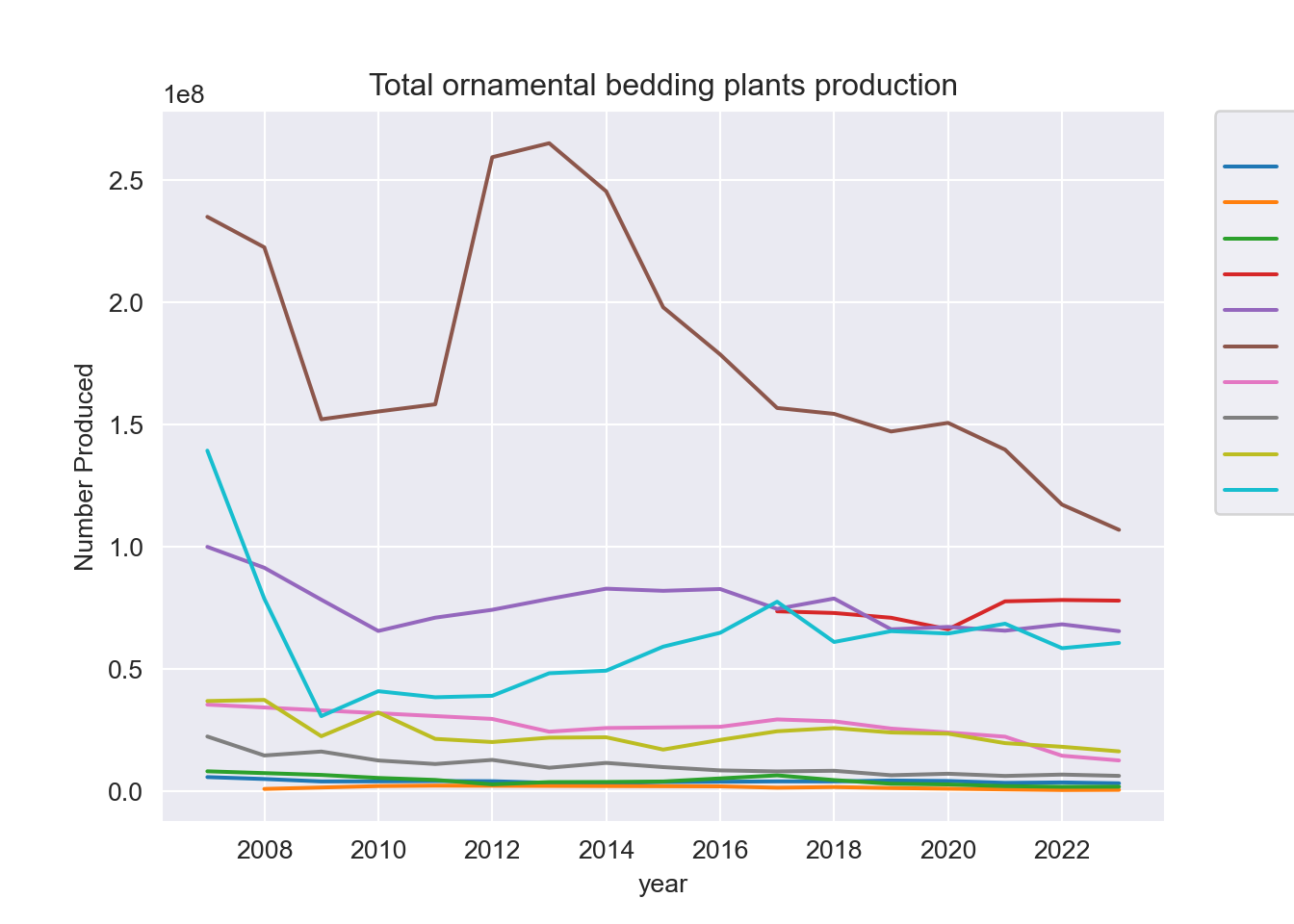
# Select the datasets of two different bedding plants (vegetable & ornamental) in 10 different provinces
plants |> subset(location != "Canada" & Output =="Production (number)" & Flowers.and.plants =="Total vegetable bedding plants [115143421]") |>
ggplot( aes(x = year, y = VALUE, group = location)) +
geom_line(aes(color = location)) +
labs(y = "Number produced")+
ggtitle("Total vegetable bedding plants production")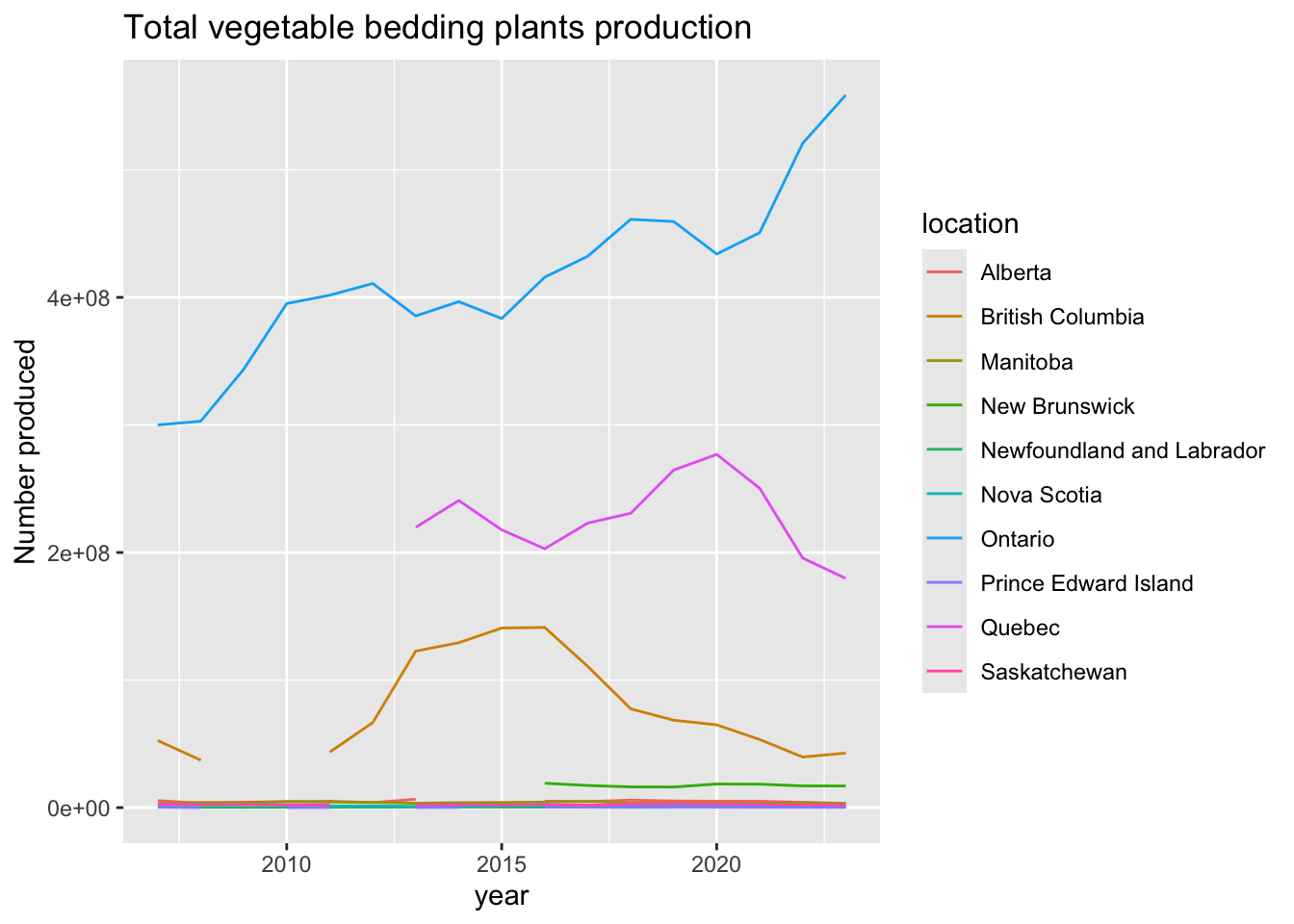
plants |> subset(location != "Canada" & Output =="Production (number)" & Flowers.and.plants =="Total ornamental bedding plants [115143411]") |>
ggplot( aes(x = year, y = VALUE, group = location)) +
geom_line(aes(color = location)) +
labs(y = "Number produced")+
ggtitle("Total ornamental bedding plants production")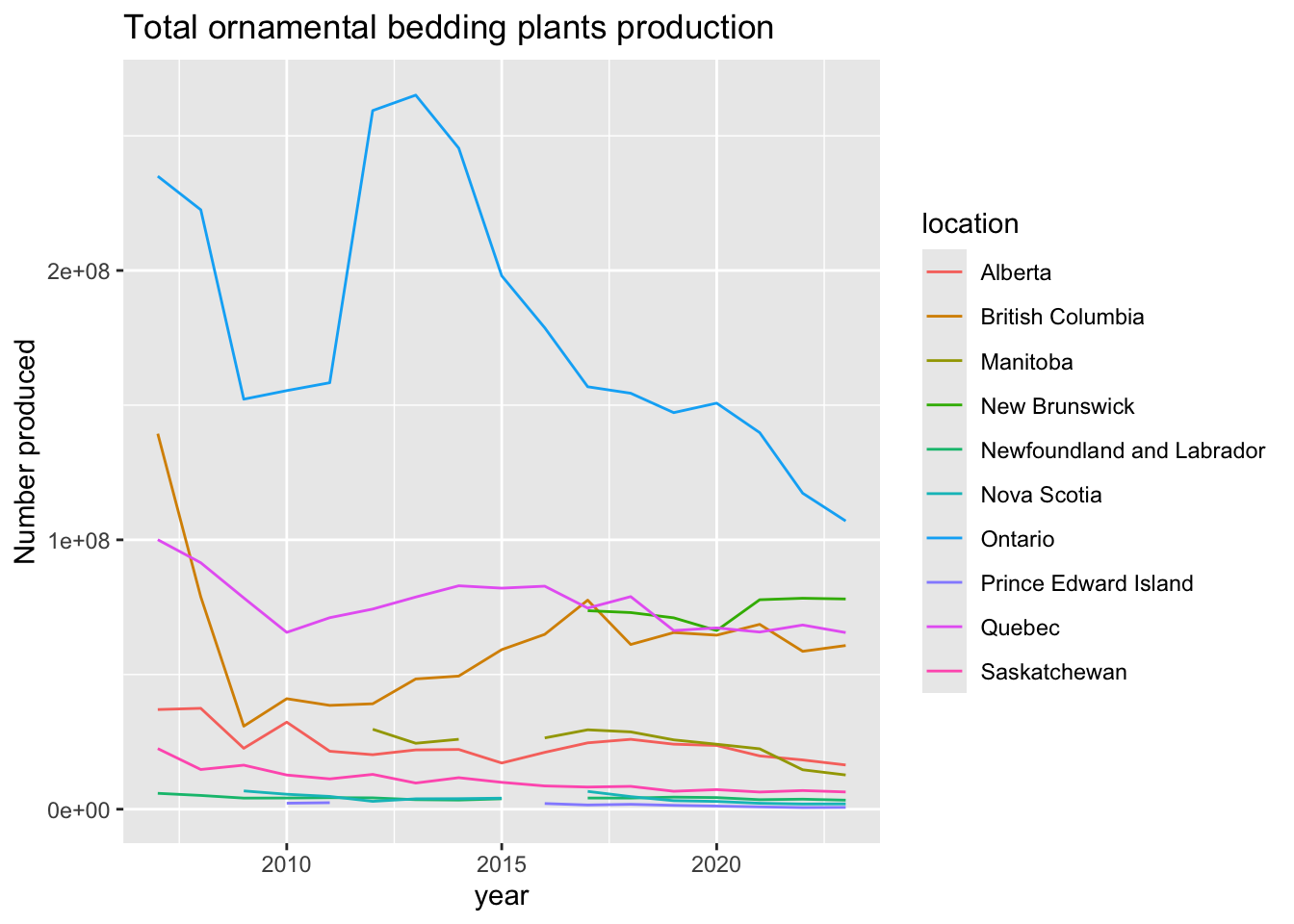
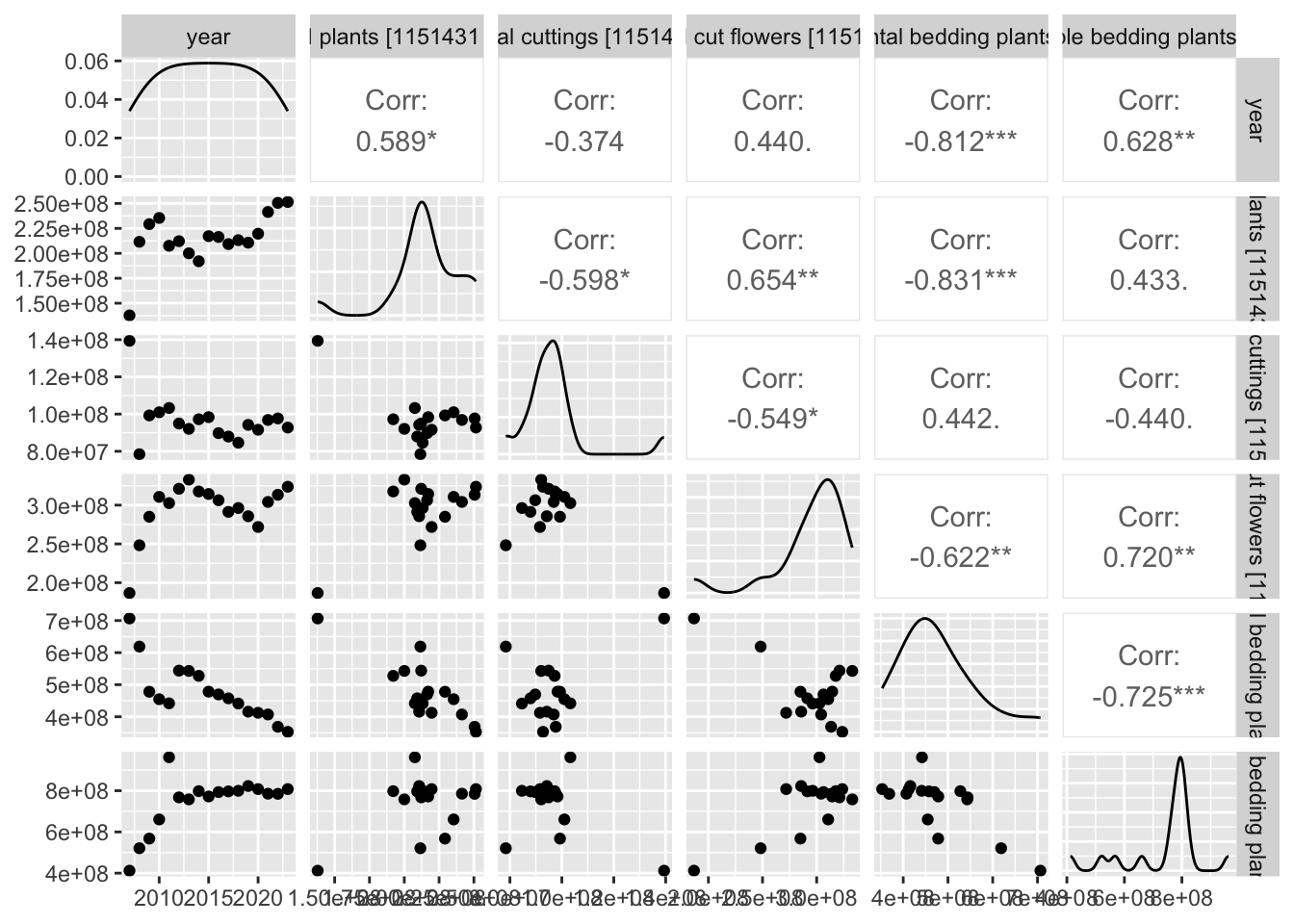
Examining all production counts within Canada
plants_2 = plants[(plants["location"] == "Canada") &
(plants["Output"] == "Sales")][["year",
"Flowers and plants",
"VALUE"]]
plants_2 = pd.pivot_table(plants_2,
values = "VALUE",
columns = "Flowers and plants",
index = "year").reset_index()
sb.pairplot(data = plants_2);
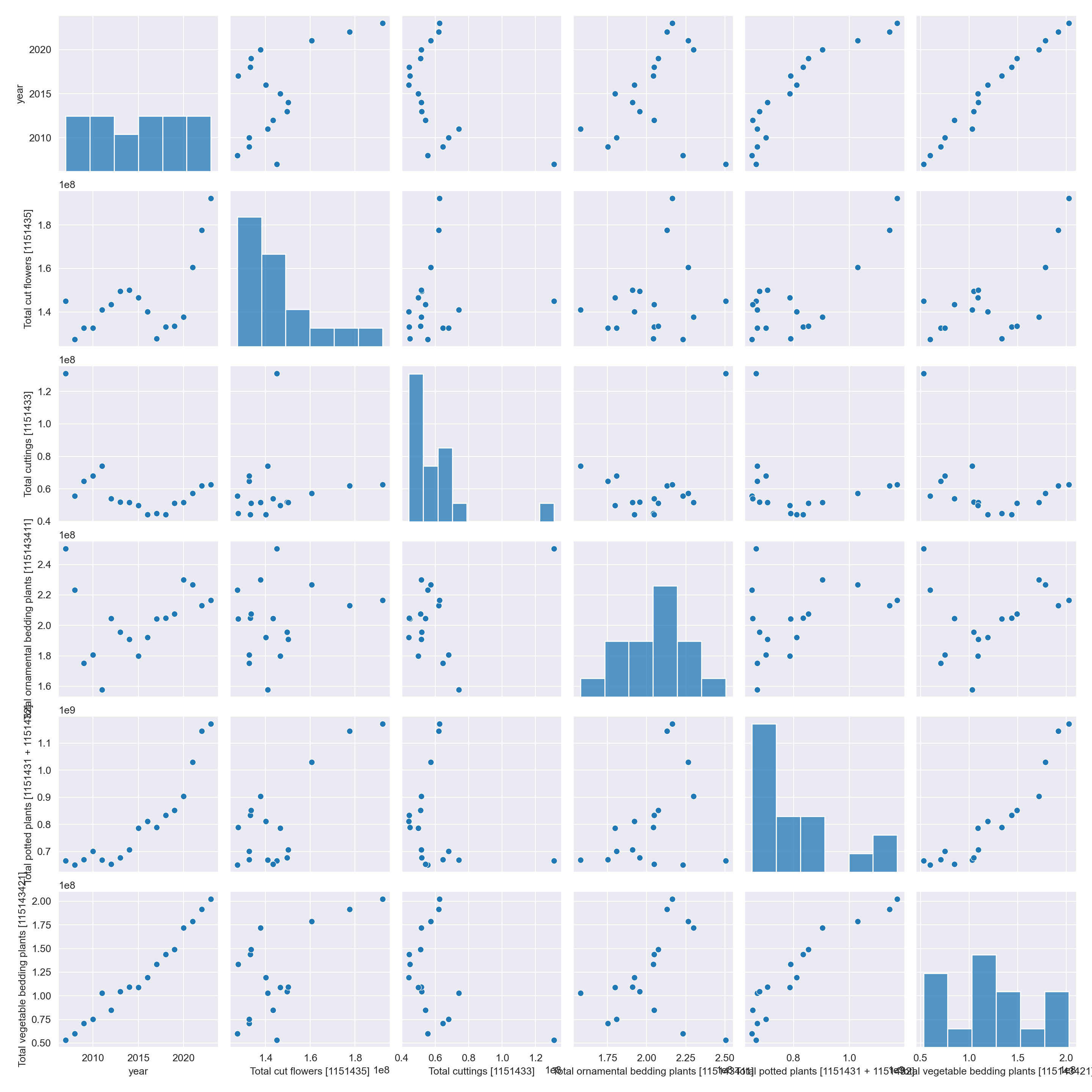
plants |> subset(location == "Canada" & Output =="Production (number)") |>
select(year, Flowers.and.plants, VALUE)|>
pivot_wider(names_from= Flowers.and.plants,values_from=VALUE) |>
ggpairs()