import requests, zipfile, io
import tempfile as tf
import pandas as pd
import seaborn as sb
import matplotlib.pyplot as pltTrade Data: Monthly Exports of Grains - Open Canada
Open Canada
zipfiles
csv files
Software:Python
Software:R
Data Provider
Statistics Canada’s Open Government is a free and open-access platform containing over 80,000 datasets across diverse subjects. The purpose of sharing all data documents with the public is to remain transparent and accessible.
Dataset can be discovered by multiple searching methods here, such as Browse by subject, Open Government Portal for direct keywords search, Open Maps which contains geospatial information data, Open Data Inventory from the government of Canada organization, Apps Gallery for representing those mobile and web-based application data, Open Data 101 for letting people know how to use dataset and so on.
Exports of Grains, by the final destination
This dataset recorded 862 observations from the year 1922 to 2017. The data is described by many dimensions, such as commodities about 9 different types of grains, export destinations of 217 countries, 10 continents(Total Western Europe, Total Asia,…) and 1 total destination (Toal exports, all destinations), the export value unit is recorded as tonnes.
The dataset and its metadata file with detailed variable descriptions have been stored together as a zip file. You can find detailed information here, and you also can quickly discover the customized table here.
Libraries
library(tidyverse)Organizing Dataset
The following code is used to extract the whole dataset of grains export from the official website and perform the linear chart of total grains export to all destinations by grouping commodities.
temp = tf.TemporaryFile()
url = "https://www150.statcan.gc.ca/n1/tbl/csv/32100008-eng.zip"
r = requests.get(url)
temp = zipfile.ZipFile(io.BytesIO(r.content))
file_list = temp.namelist()
print(file_list)['32100008.csv', '32100008_MetaData.csv']#get column names so we can chose the columns we want
meta_columns= pd.read_csv(temp.open('32100008_MetaData.csv'), nrows=0, skiprows = 8).columns.tolist()
cols = ['REF_DATE',
'GEO',
'Commodity',
'Destinations',
'VALUE']
export_data = pd.read_csv(temp.open('32100008.csv'), usecols = cols)
export_data = export_data.rename(columns = {"GEO" : "location", "REF_DATE" : "date"})
export_data["year"] = pd.to_numeric(export_data["date"].str.split("-").str[0])
export_data["month"] = pd.to_numeric(export_data["date"].str.split("-").str[1])
export_data.head() date location Commodity ... VALUE year month
0 1922-01 Canada Flaxseed ... 247.0 1922 1
1 1922-02 Canada Flaxseed ... 1436.0 1922 2
2 1922-03 Canada Flaxseed ... 588.0 1922 3
3 1922-04 Canada Flaxseed ... 322.0 1922 4
4 1922-05 Canada Flaxseed ... 12241.0 1922 5
[5 rows x 7 columns]# Download the zip file of the orginial grains export dataset
temp = tempfile()
download.file("https://www150.statcan.gc.ca/n1/tbl/csv/32100008-eng.zip",temp)
(file_list = as.character(unzip(temp, list = TRUE)$Name))[1] "32100008.csv" "32100008_MetaData.csv"meta = read_csv(unz(temp, file_list[2]), skip = 8) |> rename_all(make.names) |>
select(Dimension.ID, Member.Name, Member.ID)
export_data = read_csv(unz(temp, "32100008.csv"))
unlink(temp)
# organize the export data
export_data = export_data |>
rename(date = REF_DATE, location = GEO) |>
separate(col = date, into = c("year", "month"), sep = "-")|> # split the year-month column into two different columns
mutate(year = as.numeric(year), month = as.numeric(month)) Some exploratory plots
# Summarize the annual export value by group of the year
totals = export_data.groupby(["year",
"Commodity",
"Destinations"], as_index=False)['VALUE'].sum()
fig, ax = plt.subplots(figsize=(8, 5), constrained_layout=True)
sb.lineplot(data = totals[totals["Destinations"] == "Total exports, all destinations"],
x = "year",
y = "VALUE",
hue = "Commodity",
ax = ax)
ax.set_title("Total grains export to all destinations")
ax.set_ylabel("total export (tonnes)")
ax.legend(title="Commodity",
bbox_to_anchor=(1.05, 1),
loc='upper left',
borderaxespad=0)
plt.show();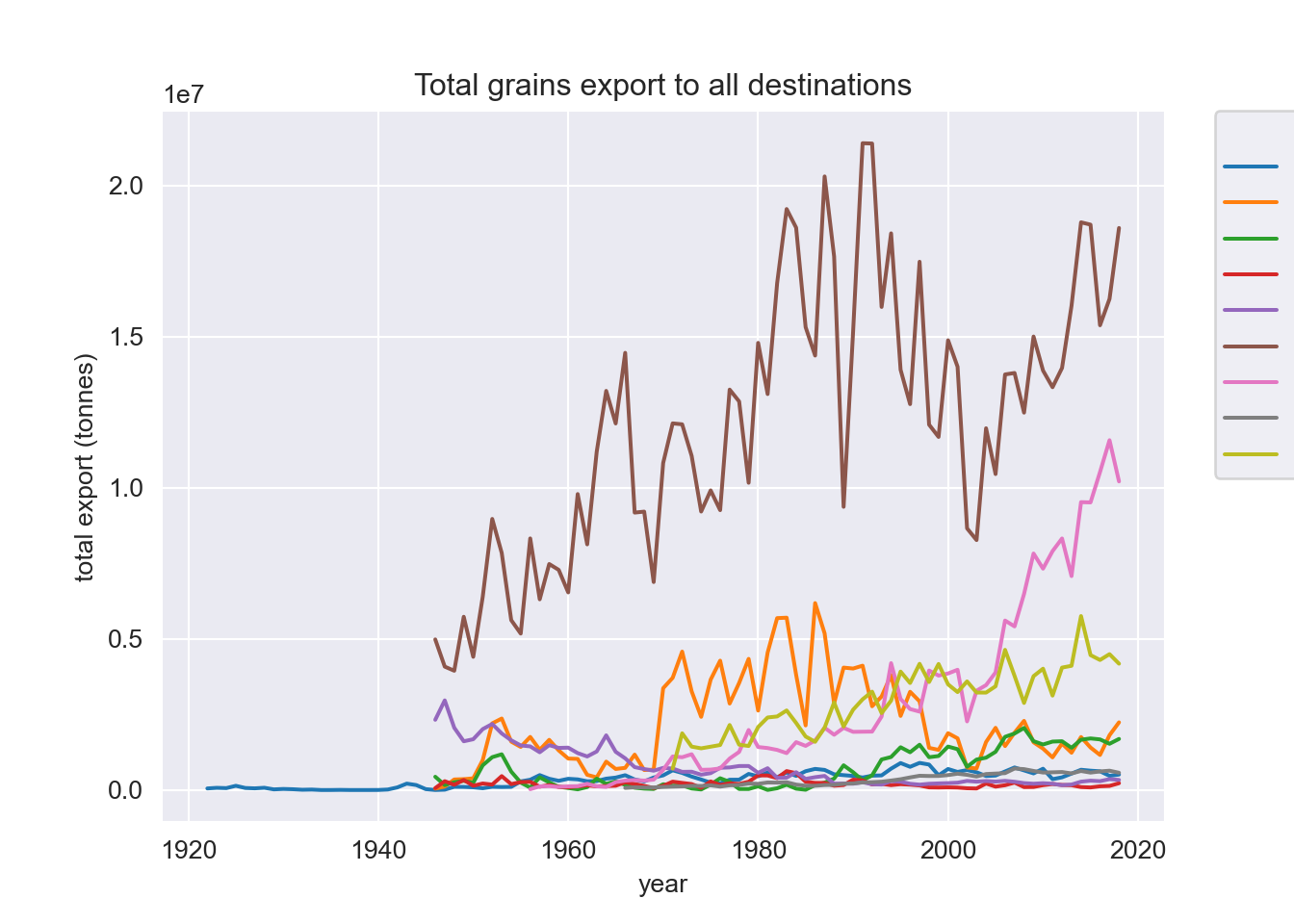
# Summarize the annual export value by group of the year
export_data |> group_by(year, Commodity, Destinations) |>
summarize(total = sum(VALUE)) |>
subset(Destinations == "Total exports, all destinations") |>
ungroup() |>
ggplot( aes(x = year, y = total, group = Commodity)) +
labs(y = "total export (tonnes)") +
geom_line(aes(color = Commodity)) +
ggtitle("Total grains export to all destinations")`summarise()` has regrouped the output.
ℹ Summaries were computed grouped by year, Commodity, and Destinations.
ℹ Output is grouped by year and Commodity.
ℹ Use `summarise(.groups = "drop_last")` to silence this message.
ℹ Use `summarise(.by = c(year, Commodity, Destinations))` for per-operation
grouping (`?dplyr::dplyr_by`) instead.
Wheat, excluding durum
The following code is used to plot total exports among different continents and then consider just the major importing countries of canola
# Select the whole export dataset about canola among different continents
wheat_ex_durum = export_data[(export_data["Commodity"] == "Wheat, excluding durum") &
(export_data["Destinations"] != "Total exports, all destinations")]
wheat_ex_durum = wheat_ex_durum[wheat_ex_durum["Destinations"].str.contains("Total")]
#wheat_ex_durum.head()
wheat_totals = wheat_ex_durum.groupby(["year",
"Commodity",
"Destinations"], as_index=False)['VALUE'].sum()
fig, ax = plt.subplots(figsize=(8, 5), constrained_layout=True)
sb.lineplot(data = wheat_totals,
x = "year",
y = "VALUE",
hue = "Destinations",
ax = ax)
ax.set_title("Total Annual Wheat, excluding durum, export among different continents")
ax.set_ylabel("total export (tonnes)")
ax.legend(title="Destinations",
bbox_to_anchor=(1.05, 1),
loc='upper left',
borderaxespad=0)
plt.show();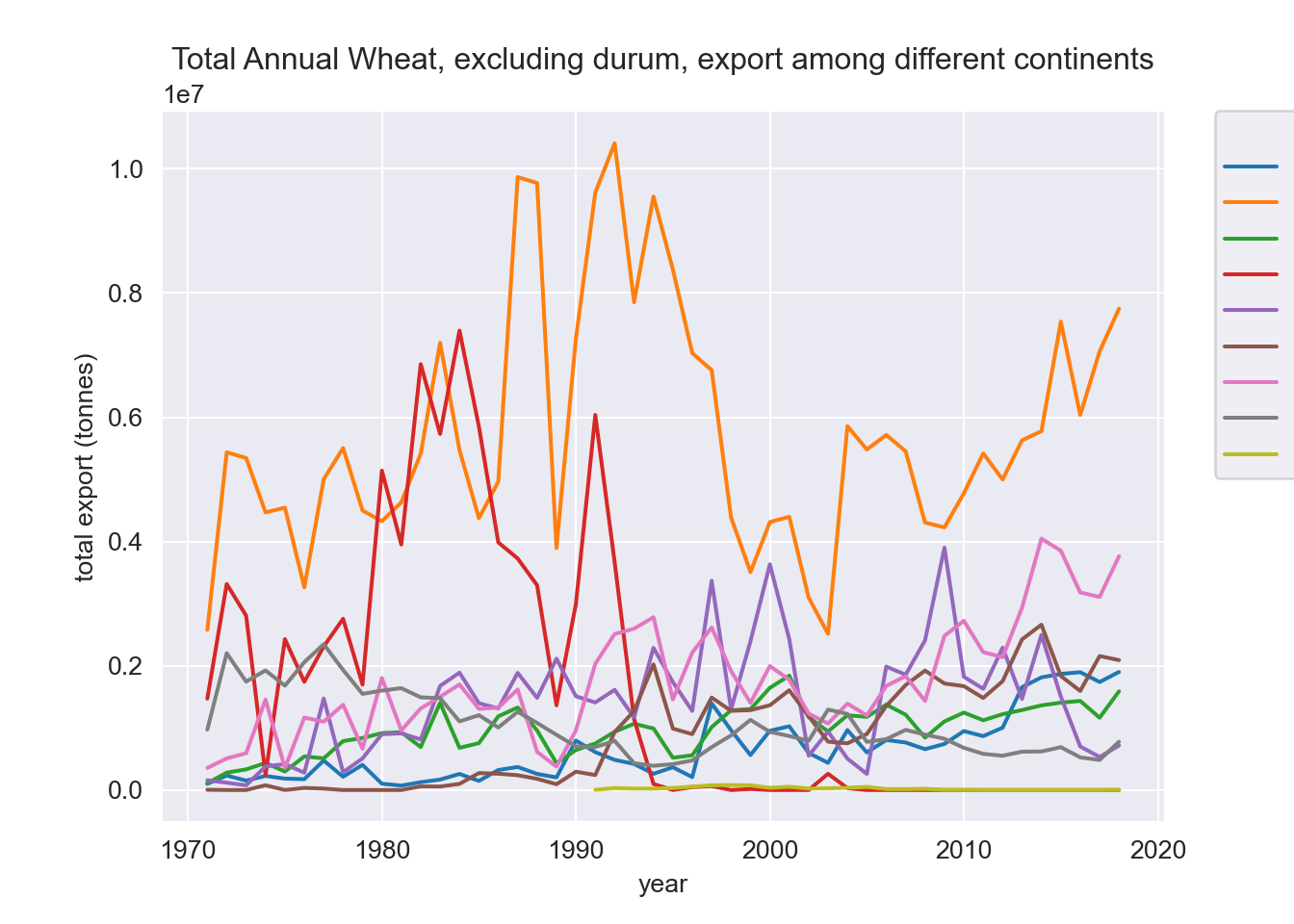
# Select the whole export dataset about canola among different continents
export_data |> subset(Commodity == "Wheat, excluding durum" & Destinations != "Total exports, all destinations") |>
filter( str_detect(Destinations, "Total")) |>
group_by(year, Commodity, Destinations) |>
summarize(total = sum(VALUE)) |>
ungroup() |>
ggplot( aes(x = year, y = total, group = Destinations)) +
labs(y = "total export (tonnes)") +
geom_line(aes(colour = Destinations)) +
ggtitle("Total Annual Wheat, excluding durum, export among different continents")`summarise()` has regrouped the output.
ℹ Summaries were computed grouped by year, Commodity, and Destinations.
ℹ Output is grouped by year and Commodity.
ℹ Use `summarise(.groups = "drop_last")` to silence this message.
ℹ Use `summarise(.by = c(year, Commodity, Destinations))` for per-operation
grouping (`?dplyr::dplyr_by`) instead.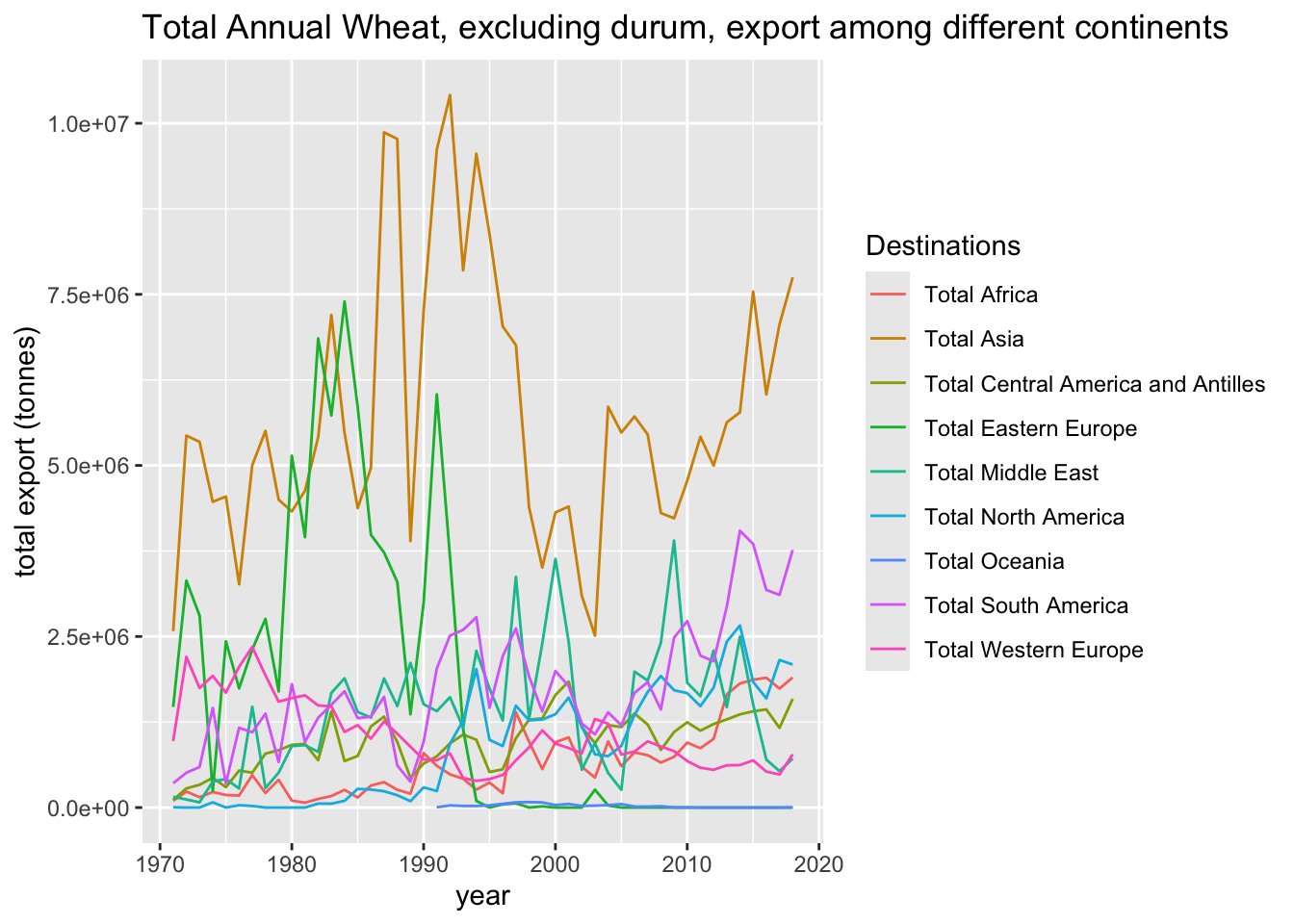
Examining Wheat (excluding durum) for a couple of countries
# Select a few contries and plot their imports
few_countries = export_data[(export_data["Commodity"] == "Wheat, excluding durum") &
((export_data["Destinations"] == "United States") |
(export_data["Destinations"] == "People's Republic of China") |
(export_data["Destinations"] == "United Kingdom") |
(export_data["Destinations"] == "United Arab Emirates") |
(export_data["Destinations"] == "India") |
(export_data["Destinations"] == "Ethiopia"))]
few_countries_totals = few_countries.groupby(["year", "Destinations"], as_index=False)['VALUE'].sum()
fig, ax = plt.subplots(figsize=(8, 5), constrained_layout=True)
sb.lineplot(data = few_countries_totals,
x = "year",
y = "VALUE",
hue = "Destinations",
ax = ax)
ax.set_title("Total Wheat, excluding durum, exported by year")
ax.set_ylabel("total export (tonnes)")
ax.legend(title="Destinations",
bbox_to_anchor=(1.05, 1),
loc='upper left',
borderaxespad=0)
plt.show();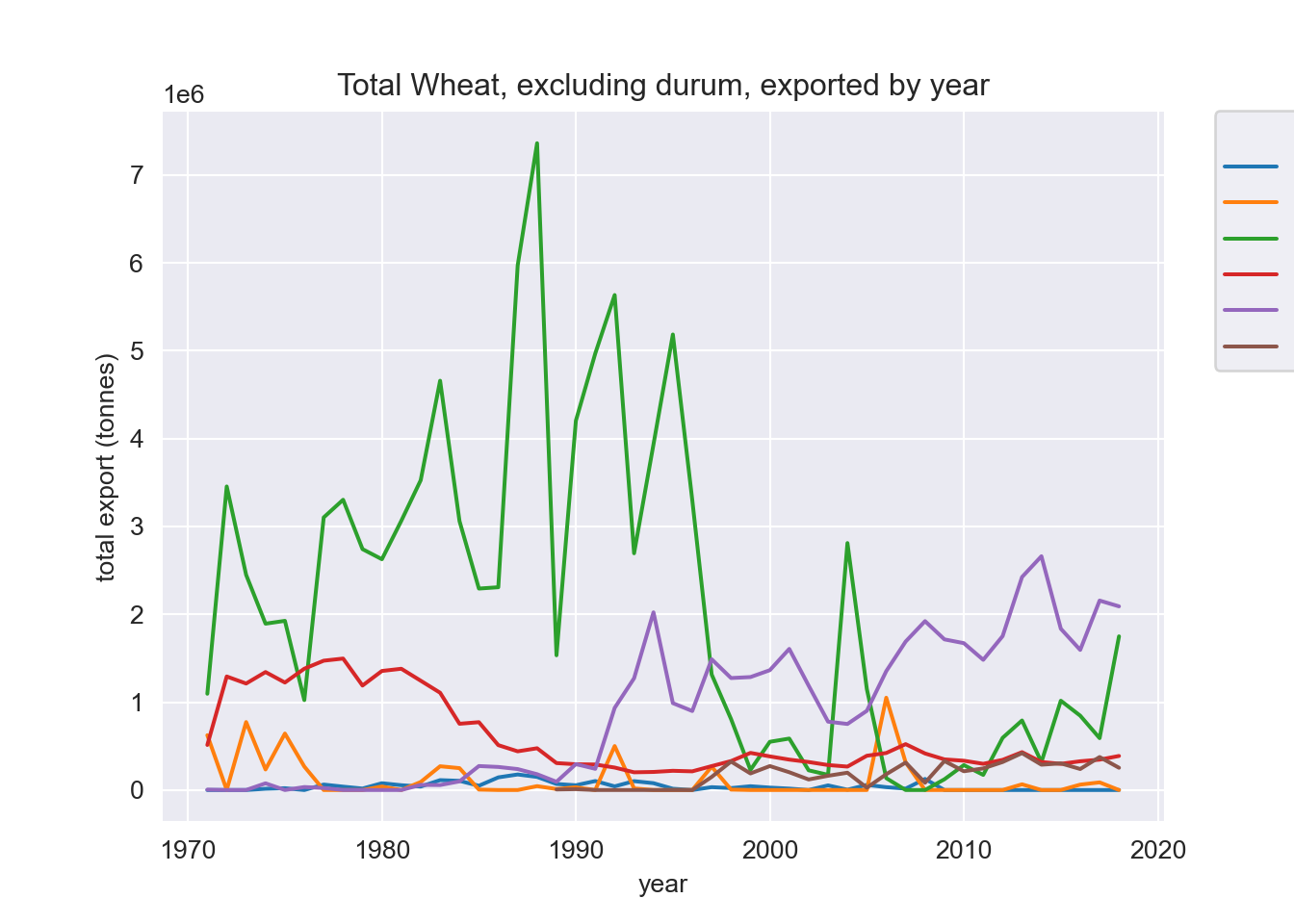
# Select a few contries and plot their imports
export_data |>
subset(Commodity == "Wheat, excluding durum" & Destinations %in% c("United States", "People's Republic of China", "United Kingdom", "United Arab Emirates", "India", "Ethiopia")) |>
group_by(year, Destinations) |>
summarize(total = sum(VALUE)) |>
ungroup() |>
ggplot( aes(x = year, y = total, group = Destinations)) +
labs(y = "total export (tonnes)") +
geom_line(aes(colour = Destinations)) +
ggtitle("Total Wheat, excluding durum, exported by year")`summarise()` has regrouped the output.
ℹ Summaries were computed grouped by year and Destinations.
ℹ Output is grouped by year.
ℹ Use `summarise(.groups = "drop_last")` to silence this message.
ℹ Use `summarise(.by = c(year, Destinations))` for per-operation grouping
(`?dplyr::dplyr_by`) instead.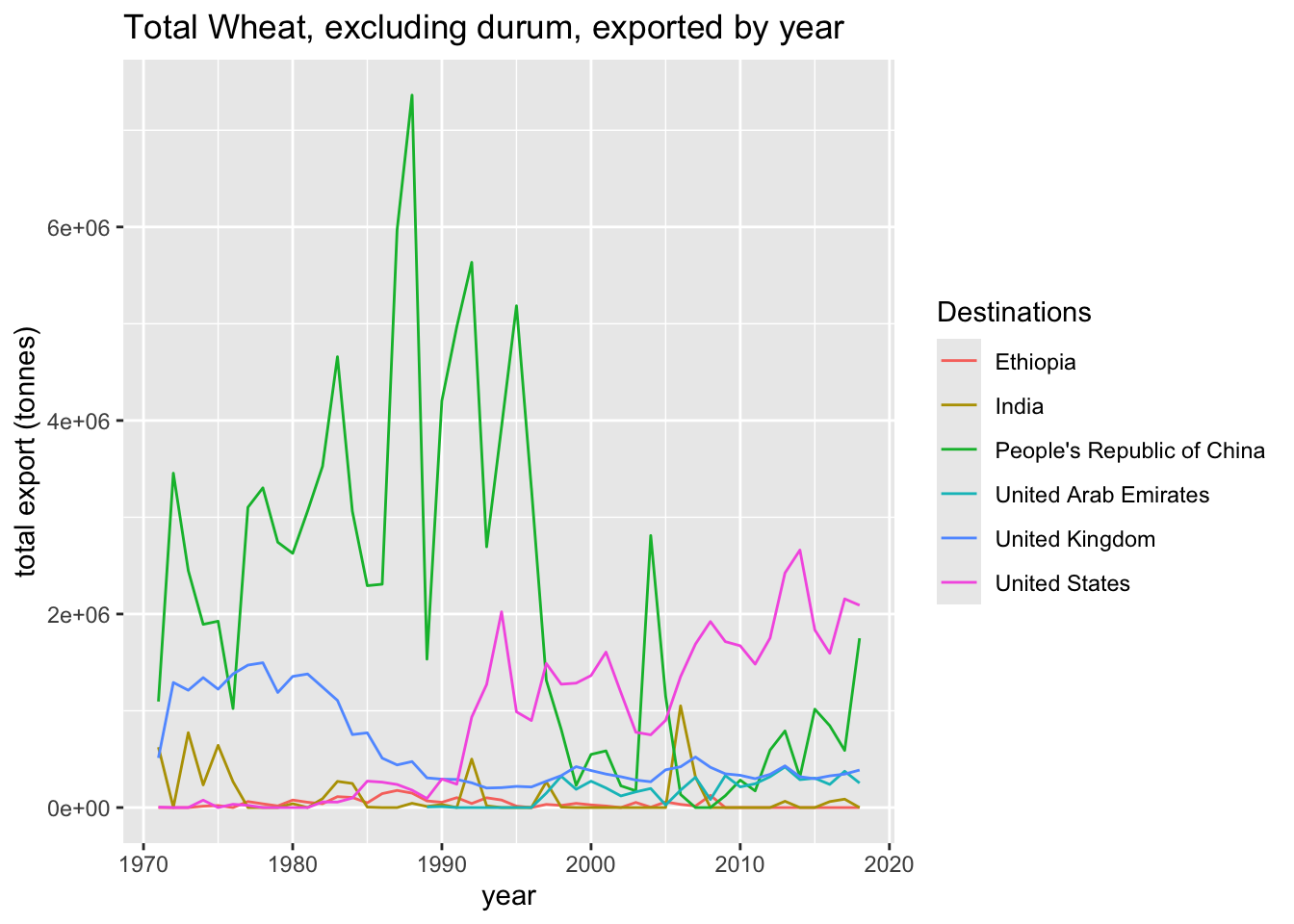
Canola
Now consider canola for countries that have imported at least 1,000,000 tonnes in at least one year and plot all of their annual import data.
tmp_exports = export_data[(export_data["Commodity"] == "Canola (rapeseed)") &
(export_data["Destinations"] != "Total exports, all destinations")]
tmp_exports = tmp_exports.groupby(["year",
"Commodity",
"Destinations"],
as_index=False)['VALUE'].sum()
tmp_exports = tmp_exports[tmp_exports["Destinations"].str.contains("Total") == False]
big_countries = tmp_exports[tmp_exports["VALUE"] > 1000000]["Destinations"].unique()
tmp_exports = tmp_exports[tmp_exports["Destinations"].isin(big_countries)]
fig, ax = plt.subplots(figsize=(8, 5), constrained_layout=True)
sb.lineplot(data = tmp_exports,
x = "year",
y = "VALUE",
hue = "Destinations",
ax = ax)
ax.set_title("Total Canola (rapeseed), for countries that have "
"surpassed 1,000,000 tonnes imported in at least one year")
ax.set_ylabel("total export (tonnes)")
ax.legend(title="Destinations", bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0)
plt.show();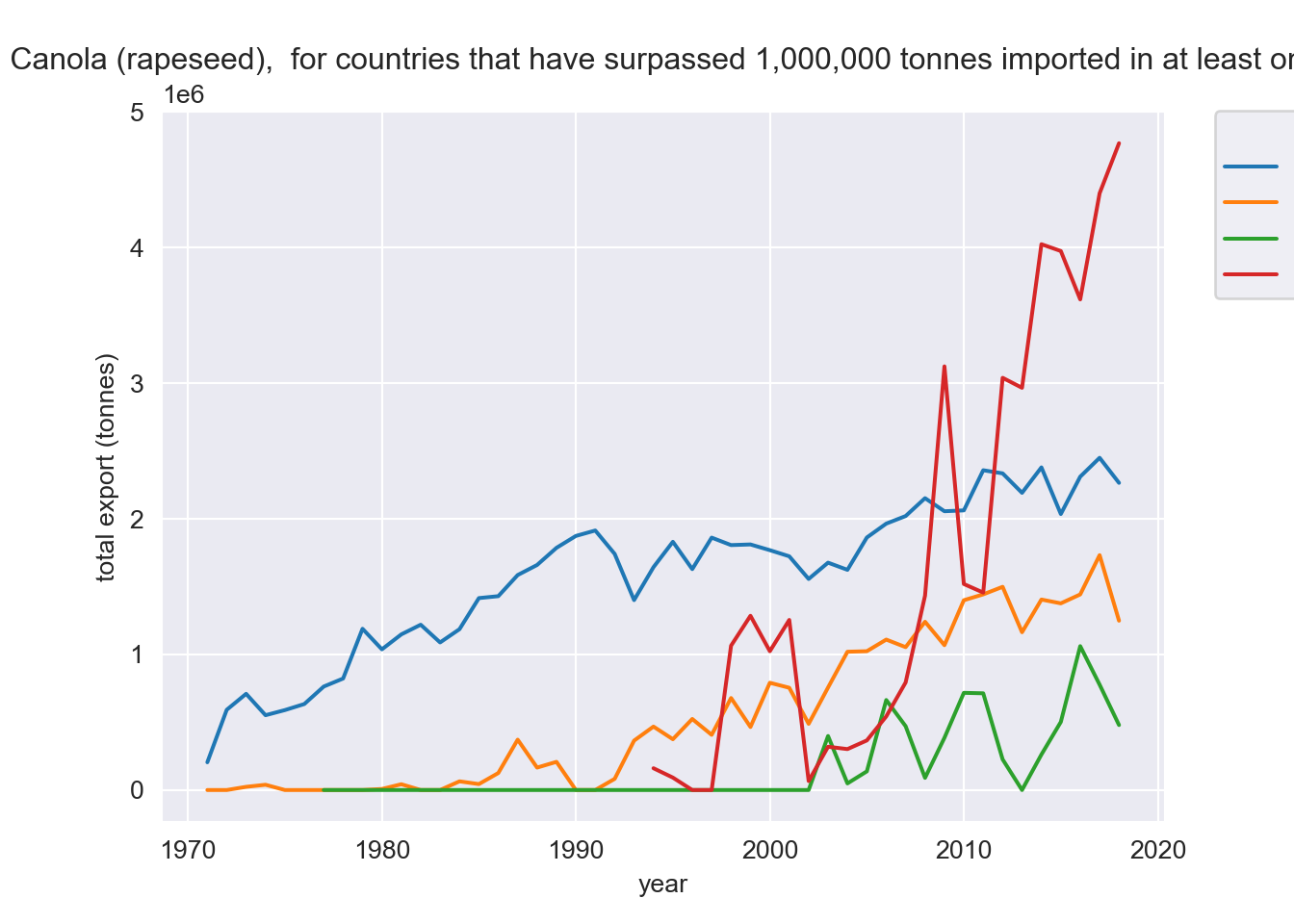
tmp_exports = export_data |>
subset(Commodity == "Canola (rapeseed)" & Destinations != "Total exports, all destinations") |>
group_by(year, Commodity, Destinations) |>
summarize(total = sum(VALUE)) |>
ungroup() |>
subset(str_detect(Destinations, "Total") == "FALSE")`summarise()` has regrouped the output.
ℹ Summaries were computed grouped by year, Commodity, and Destinations.
ℹ Output is grouped by year and Commodity.
ℹ Use `summarise(.groups = "drop_last")` to silence this message.
ℹ Use `summarise(.by = c(year, Commodity, Destinations))` for per-operation
grouping (`?dplyr::dplyr_by`) instead.# find all the countries that surpass 1,000,000 tonnes in at least one year, but keep all of the data for those countries
big_countries = tmp_exports |>
subset(total > 1000000) |>
select(Destinations) |>
unique()
#Subset to just keep the "big" destination countries
tmp_exports |>
subset(Destinations %in% big_countries$Destinations) |>
ggplot( aes(x = year, y = total, group = Destinations)) +
labs(y = "total export (tonnes)") +
geom_line(aes(color = Destinations)) +
ggtitle("Total Canola (rapeseed), for countries that have surpassed 1,000,000 tonnes imported in at least one year")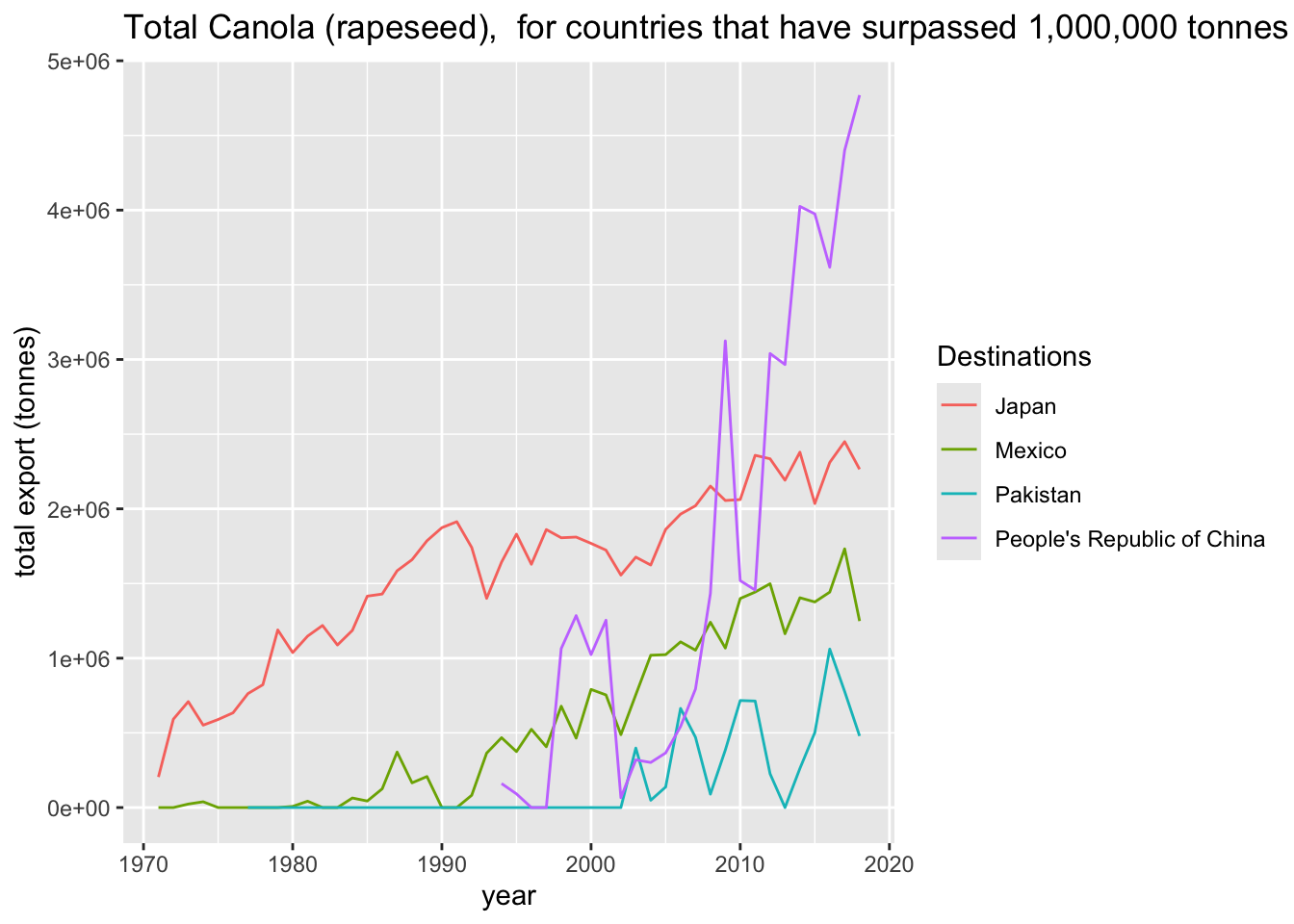
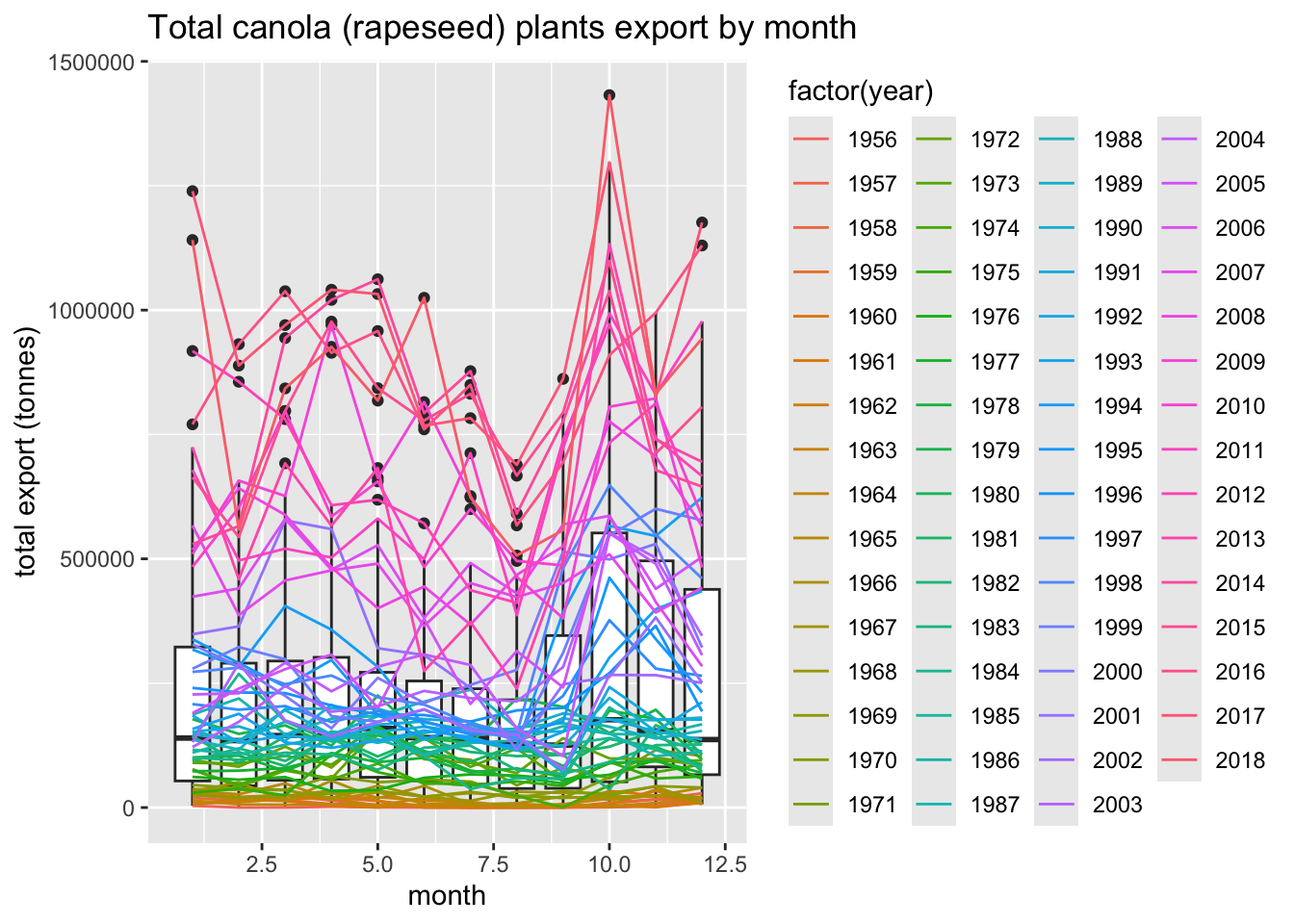
Look at Canola export by month
canola = export_data[(export_data["Commodity"] == "Canola (rapeseed)") &
(export_data["Destinations"] == "Total exports, all destinations")]
fig, ax = plt.subplots(figsize=(8, 5), constrained_layout=True)
canola_plot = sb.lineplot(data = canola,
x = "month",
y = "VALUE",
hue = "year",
linewidth = 0.8,
ax = ax)
sb.boxplot(data = canola,
x = "month",
y = "VALUE",
fill = False,
linewidth = 0.8,
color = "#137",
ax = ax)
ax.set_title("Total canola (rapeseed) plants export by month")
ax.set_ylabel("total export (tonnes)")
ax.legend(title="Years",
bbox_to_anchor=(1.05, 1),
loc='upper left',
borderaxespad=0)
plt.show();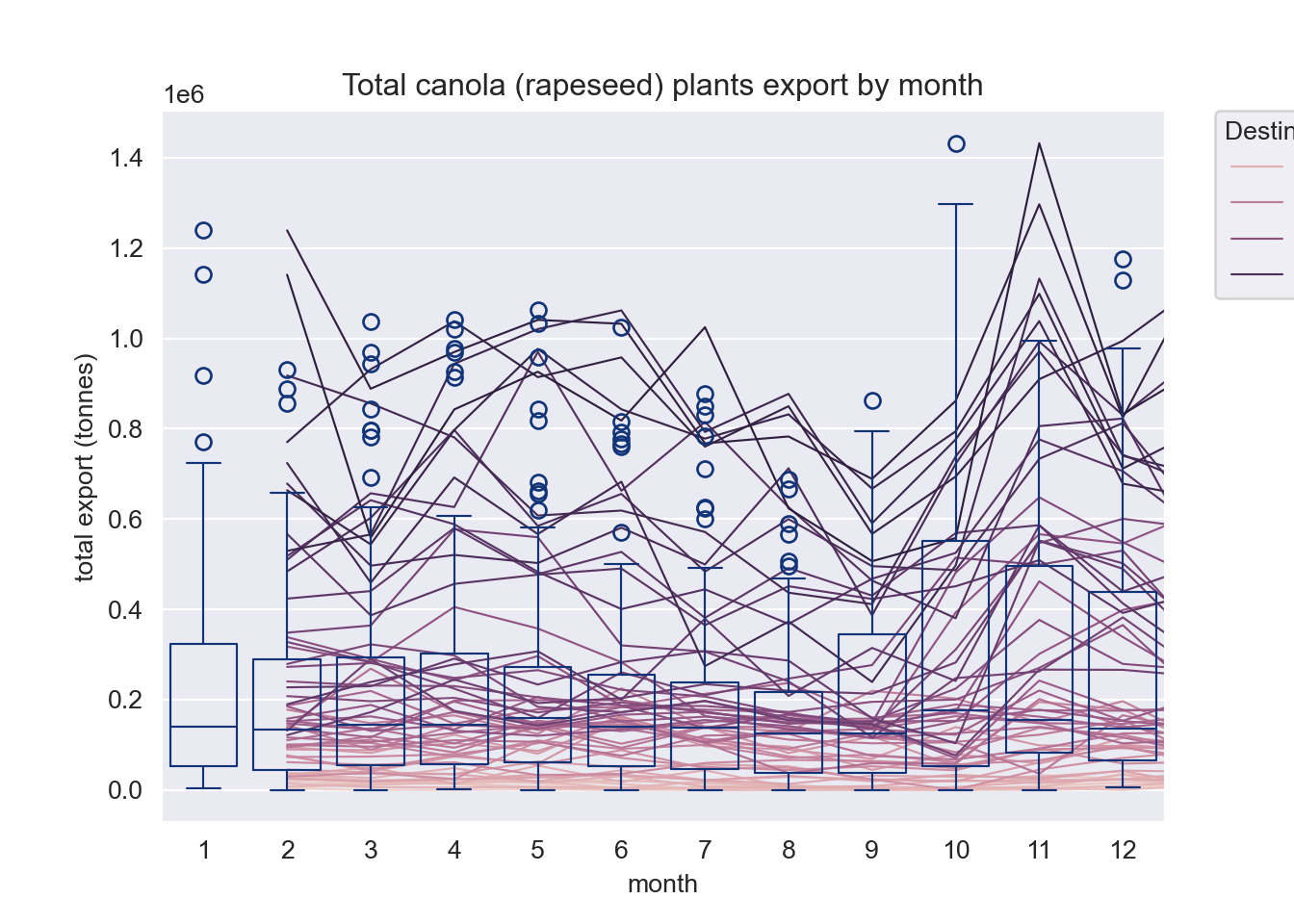
export_data |>
subset(Commodity == "Canola (rapeseed)") |>
filter( str_detect(Destinations, "Total exports, all destinations")) |>
ggplot() +
geom_boxplot(aes(group = month, y = VALUE, x=month)) +
geom_line(aes(x = month, group = year, y = VALUE, colour=factor(year)))+
ggtitle("Total canola (rapeseed) plants export by month")+
labs(y = "total export (tonnes)")